Publications
This section lists the selections of my publications in time order.
You can also find my articles on my Google Scholar profile, and my academic activities on my ORCID.
* denotes equal contribution, † denotes corresponding author.
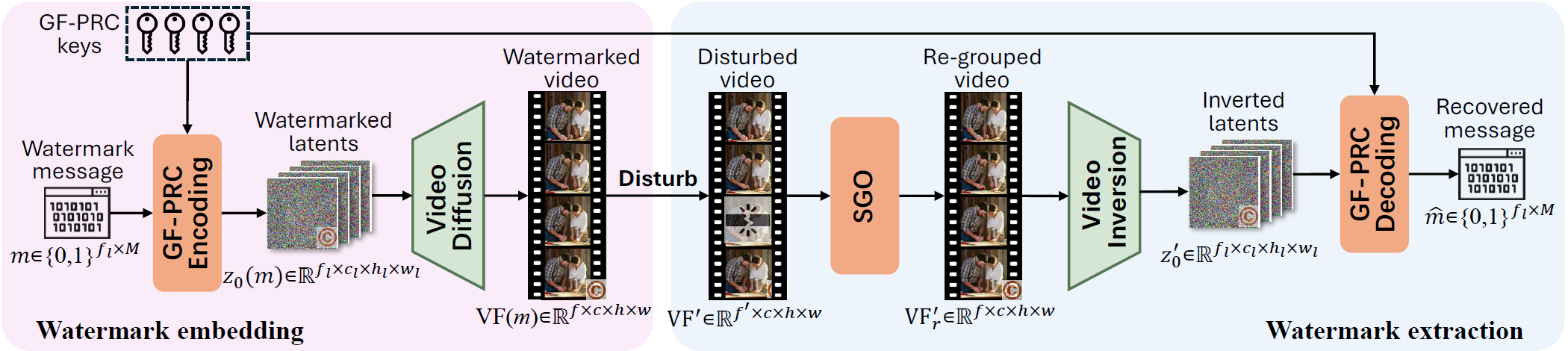
SIGMark: Scalable In-Generation Watermark with Blind Extraction for Video Diffusion
Xinjie Zhu*, Zijing Zhao*, Hui Jin, Qingxiao Guo, Yilong Ma, Yunhao Wang, Xiaobing Guo, Weifeng Zhang†
Published as a conference paper at International Conference on Learning Representations (ICLR 2026)
[homepage] [arxiv] [pdf] [supp] [code]
Abstract (Click to unfold):
Artificial Intelligence Generated Content (AIGC), particularly video generation with diffusion models, has been advanced rapidly. Invisible watermarking is a key technology for protecting AI-generated videos and tracing harmful content, and thus plays a crucial role in AI safety. Beyond post-processing watermarks which inevitably degrade video quality, recent studies have proposed distortion-free in-generation watermarking for video diffusion models. However, existing in-generation approaches are non-blind: they require maintaining all the message-key pairs and performing template-based matching during extraction, which incurs prohibitive computational costs at scale. Moreover, when applied to modern video diffusion models with causal 3D Variational Autoencoders (VAEs), their robustness against temporal disturbance becomes extremely weak. To overcome these challenges, we propose SIGMark, a Scalable In-Generation watermarking framework with blind extraction for video diffusion. To achieve blind-extraction, we propose to generate watermarked initial noise using a Global set of Frame-wise PseudoRandom Coding keys (GF-PRC), reducing the cost of storing large-scale information while preserving noise distribution and diversity for distortion-free watermarking. To enhance robustness, we further design a Segment Group-Ordering module (SGO) tailored to causal 3D VAEs, ensuring robust watermark inversion during extraction under temporal disturbance. Comprehensive experiments on modern diffusion models show that SIGMark achieves very high bit-accuracy during extraction under both temporal and spatial disturbances with minimal overhead, demonstrating its scalability and robustness.Confidence-Aware Pseudo-Label Self-Correction for Weakly Supervised Visual Grounding
Yang Liu, Jiahua Zhang, Yue Wu, Zijing Zhao, Qingchao Chen, Yuxin Peng†
Published in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2026)
[ieee]
Abstract (Click to unfold):
Weakly supervised visual grounding aims to locate a region in an image based on an input query sentence, without access to the mapping between image regions and queries during training. Current methods treat spatial grounding as an object retrieval task, relying on cross-modal similarity scores for proposal selection. However, they fail to address model overfitting caused by unreliable cross-modal similarity scores. To overcome this, we first propose the Confidence-aware Pseudo-label Learning (CPL) framework. CPL first generates diverse pseudo queries for region proposals, and then establishes reliable associations for model training based on the uni-modal similarity score. Secondly, we propose a cross-modal verification module based on the pretrained vision-language model to verify associations. However, the verification module is isolated from the grounding model, so it can only assess associations in a static manner, but not correct the suspicious ones. Finally, we introduce CPL++ to make two-fold improvements. For one thing, we upgrade the verification process based on the model's grounding loss value to identify suspicious associations dynamically and selectively leverage them in the training. For another, we propose a self-supervised association correction module to rectify suspicious associations, thereby mitigating the risk of error propagation. Experimental results on five datasets demonstrate the superiority of our approach.Investigating Domain Gaps for Indoor 3D Object Detection
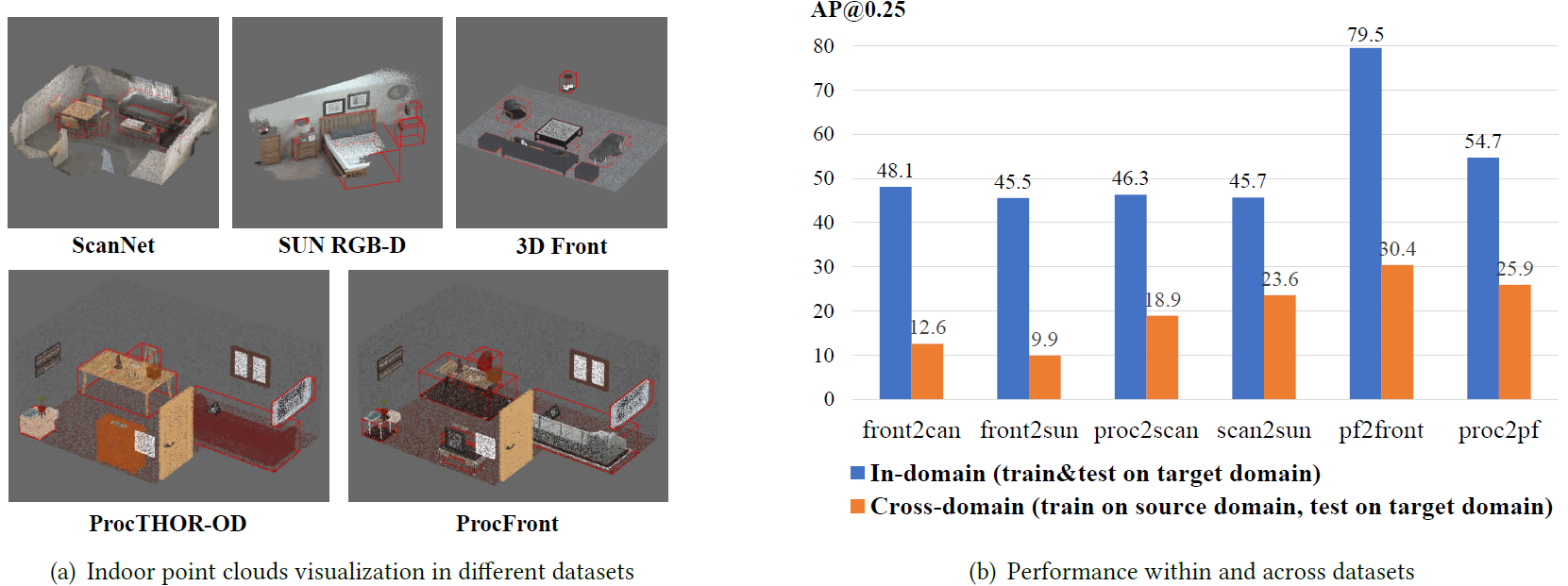
Zijing Zhao, Zhu Xu, Qingchao Chen, Yuxin Peng, Yang Liu†
Published on ACM International Conference on Multimedia (ACM MM 2025) (CCF-A)
[arxiv] [code] [homepage]
Abstract (Click to unfold):
As a fundamental task for indoor scene understanding, 3D object detection has been extensively studied, and the accuracy on indoor point cloud data has been substantially improved. However, existing researches have been conducted on limited datasets, where the training and testing sets share the same distribution. In this paper, we consider the task of adapting indoor 3D object detectors from one dataset to another, presenting a comprehensive benchmark with ScanNet, SUN RGB-D and 3D Front datasets, as well as our newly proposed large-scale datasets ProcTHOR-OD and ProcFront generated by a 3D simulator. Since indoor point cloud datasets are collected and constructed in different ways, the object detectors are likely to overfit to specific factors within each dataset, such as point cloud quality, bounding box layout and instance features. We conduct experiments across datasets on different adaptation scenarios including synthetic-to-real adaptation, point cloud quality adaptation, layout adaptation and instance feature adaptation, analyzing the impact of different domain gaps on 3D object detectors. We also introduce several approaches to improve adaptation performances, providing baselines for domain adaptive indoor 3D object detection, hoping that future works may propose detectors with stronger generalization ability across domains.Zero Shot Domain Adaptive Semantic Segmentation by Synthetic Data Generation and Progressive Adaptation
Jun Luo, Zijing Zhao, Yang Liu†
Published on IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025) (Oral)
[arxiv] [code]

Abstract (Click to unfold):
Deep learning-based semantic segmentation models achieve impressive results yet remain limited in handling distribution shifts between training and test data. In this paper, we present SDGPA (Synthetic Data Generation and Progressive Adaptation), a novel method that tackles zero-shot domain adaptive semantic segmentation, in which no target images are available, but only a text description of the target domain's style is provided. To compensate for the lack of target domain training data, we utilize a pretrained off-the-shelf text-to-image diffusion model, which generates training images by transferring source domain images to target style. Directly editing source domain images introduces noise that harms segmentation because the layout of source images cannot be precisely maintained. To address inaccurate layouts in synthetic data, we propose a method that crops the source image, edits small patches individually, and then merges them back together, which helps improve spatial precision. Recognizing the large domain gap, SDGPA constructs an augmented intermediate domain, leveraging easier adaptation subtasks to enable more stable model adaptation to the target domain. Additionally, to mitigate the impact of noise in synthetic data, we design a progressive adaptation strategy, ensuring robust learning throughout the training process. Extensive experiments demonstrate that our method achieves state-of-the-art performance in zero-shot semantic segmentation.AR-VRM: Imitating Human Motions for Visual Robot Manipulation with Analogical Reasoning
Dejie Yang, Zijing Zhao, Yang Liu†
Published on The IEEE/CVF International Conference on Computer Vision (ICCV 2025) (CCF-A)
[arxiv] [code] [homepage]
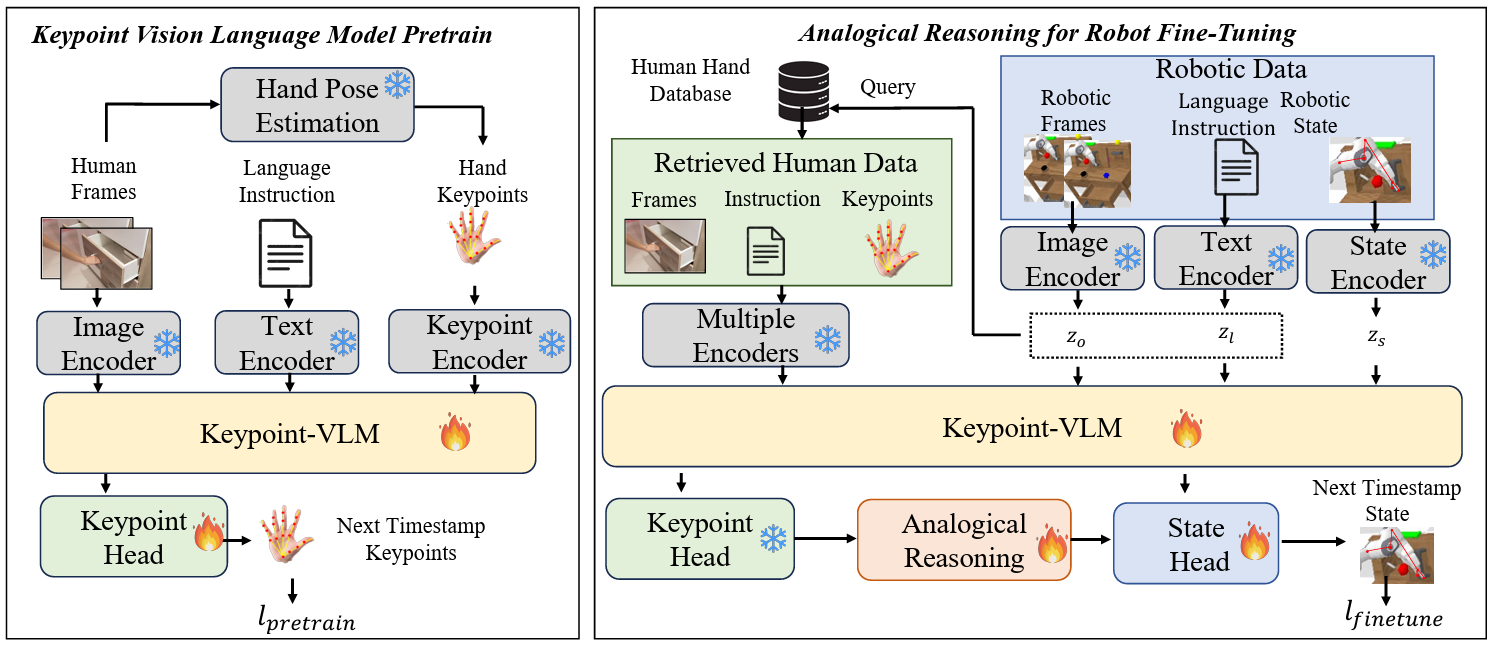
Abstract (Click to unfold):
Visual Robot Manipulation (VRM) aims to enable a robot to follow natural language instructions based on robot states and visual observations, and therefore requires costly multi-modal data. To compensate for the deficiency of robot data, existing approaches have employed vision-language pretraining with large-scale data. However, they either utilize web data that differs from robotic tasks, or train the model in an implicit way (e.g., predicting future frames at the pixel level), thus showing limited generalization ability under insufficient robot data. In this paper, we propose to learn from large-scale human action video datasets in an explicit way (i.e., imitating human actions from hand keypoints), introducing Visual Robot Manipulation with Analogical Reasoning (AR-VRM). To acquire action knowledge explicitly from human action videos, we propose a keypoint Vision-Language Model (VLM) pretraining scheme, enabling the VLM to learn human action knowledge and directly predict human hand keypoints. During fine-tuning on robot data, to facilitate the robotic arm in imitating the action patterns of human motions, we first retrieve human action videos that perform similar manipulation tasks and have similar historical observations, and then learn the Analogical Reasoning (AR) map between human hand keypoints and robot components. Taking advantage of focusing on action keypoints instead of irrelevant visual cues, our method achieves leading performance on the CALVIN benchmark and real-world experiments. In few-shot scenarios, our AR-VRM outperforms previous methods by large margins, underscoring the effectiveness of explicitly imitating human actions under data scarcity.PlanLLM: Video Procedure Planning with Refinable Large Language Models
Dejie Yang, Zijing Zhao, Yang Liu†
Published on The AAAI Conference on Artificial Intelligence (AAAI 2025) (CCF-A)
[pdf] [code] [project page]
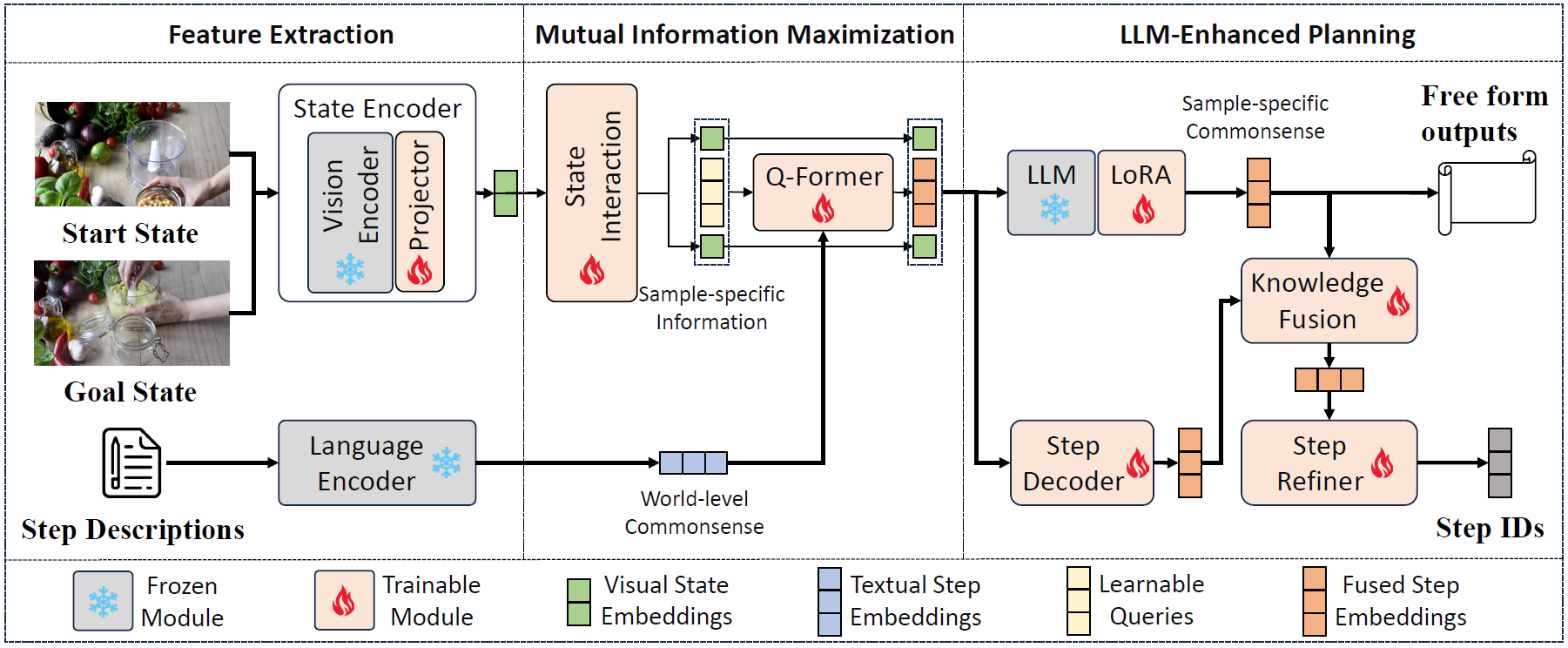
Abstract (Click to unfold):
Video procedure planning, ie, planning a sequence of action steps given the video frames of start and goal states, is an essential ability for embodied AI. Recent works utilize Large Language Models (LLMs) to generate enriched action step description texts to guide action step decoding. Although LLMs are introduced these methods decode the action steps into a closed-set of one-hot vectors, limiting the model's capability of generalizing to new steps or tasks. Additionally, fixed action step descriptions based on world-level commonsense may contain noise in specific instances of visual states. In this paper, we propose PlanLLM, a cross-modal joint learning framework with LLMs for video procedure planning. We propose an LLM-Enhanced Planning module which fully uses the generalization ability of LLMs to produce free-form planning output and to enhance action step decoding. We also propose Mutual Information Maximization module to connect world-level commonsense of step descriptions and sample-specific information of visual states, enabling LLMs to employ the reasoning ability to generate step sequences. With the assistance of LLMs, our method can both closed-set and open vocabulary procedure planning tasks. Our PlanLLM achieves superior performance on three benchmarks, demonstrating the effectiveness of our designs.Masked Retraining Teacher-student Framework for Domain Adaptive Object Detection
Zijing Zhao, Sitong Wei, Qingchao Chen, Dehui Li, Yifan Yang, Yuxin Peng, Yang Liu†
Published on International Conference on Computer Vision (ICCV 2023) (CCF-A)
[pdf] [supp] [code] [homepage]
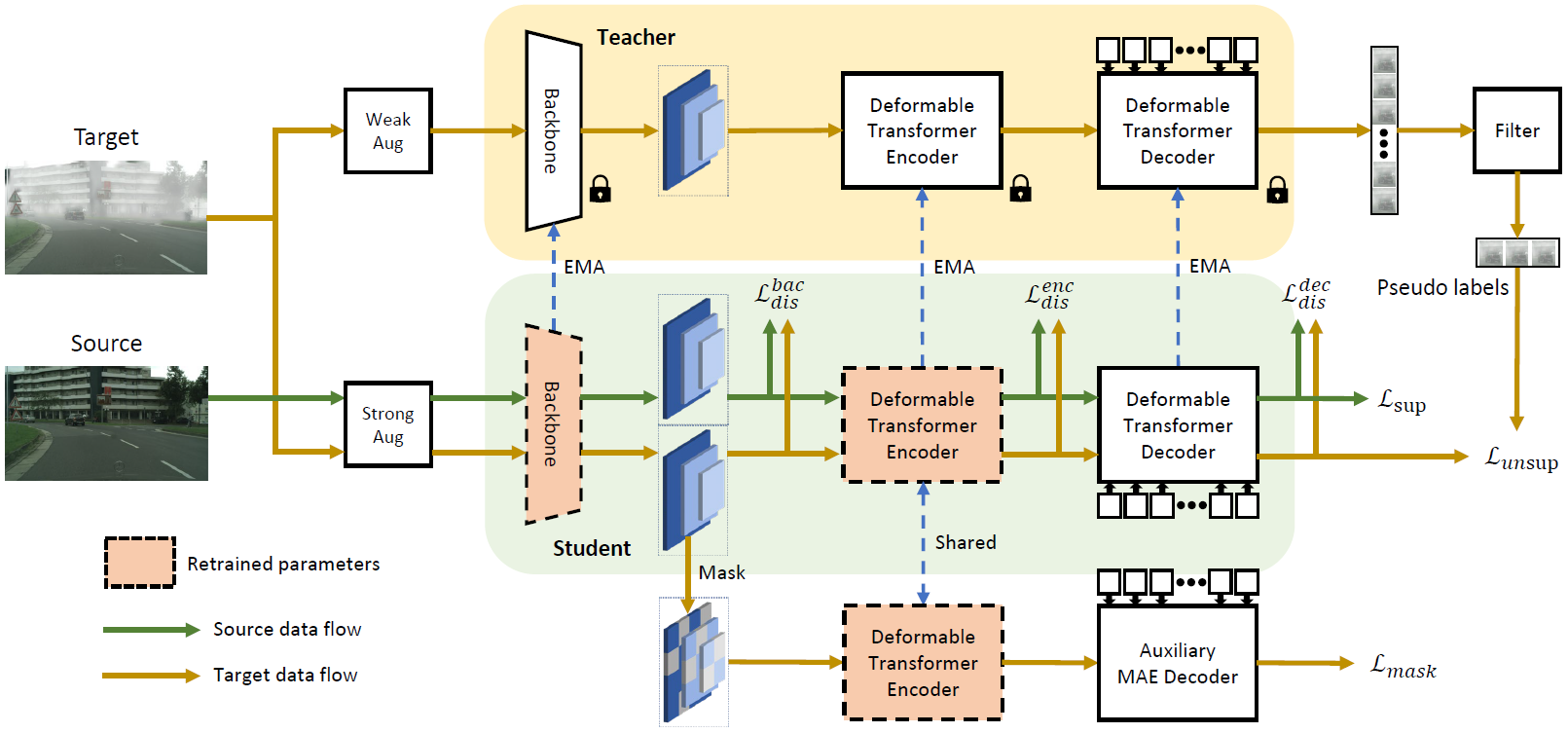
Abstract (Click to unfold):
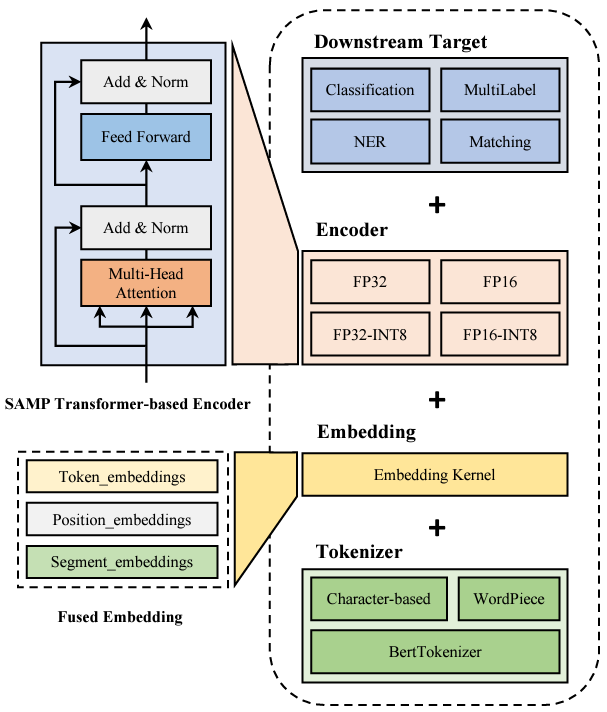
Domain adaptive Object Detection (DAOD) leverages a labeled domain (source) to learn an object detector generalizing to a novel domain without annotation (target). Recent advances use a teacher-student framework, i.e., a student model is supervised by the pseudo labels from a teacher model. Though great success, they suffer from the limited number of pseudo boxes with incorrect predictions caused by the domain shift, misleading the student model to get sub-optimal results. To mitigate this problem, we propose Masked Retraining Teacher-student framework (MRT) which leverages masked autoencoder and selective retraining mechanism on detection transformer. Specifically, we present a customized design of masked autoencoder branch, masking the multi-scale feature maps of target images and reconstructing features by the encoder of the student model and an auxiliary decoder. This helps the student model capture target domain characteristics and become a more data-efficient learner to gain knowledge from the limited number of pseudo boxes. Furthermore, we adopt selective retraining mechanism, periodically re-initializing certain parts of the student parameters with masked autoencoder refined weights to allow the model to jump out of the local optimum biased to the incorrect pseudo labels. Experimental results on three DAOD benchmarks demonstrate the effectiveness of our method.SAMP: A Model Inference Toolkit of Post-Training Quantization for Text Processing via Self-Adaptive Mixed-Precision
Rong Tian†, Zijing Zhao, Weijie Liu, Haoyan Liu, Weiquan Mao, Zhe Zhao, Kan Zhou
Published on Conference on Empirical Methods in Natural Language Processing: Industry Track (EMNLP 2023) (CCF-B)
[pdf]